
The GATOS Workflow: Can Open-Source AI Help Scale Thematic Analysis?
- Yuan Ren
- 3 days ago
- 5 min read

Why GATOS Matters
Qualitative data are often where social scientists go when numbers are not enough. Open-ended survey responses, interviews, and written reflections can capture forms of meaning that are difficult to reduce to numbers. As Saldaña (2011) argues, qualitative data analysis is fundamentally a process of meaning-making: researchers construct patterns, identify relationships, and move between inductive and deductive forms of reasoning.
The difficulty is that this work is slow. Coding qualitative data usually requires researchers to read, interpret, compare, revise, and organize large amounts of text by hand. This process is valuable precisely because it is careful, but it does not scale easily when researchers face thousands of open-ended responses. This tension provides the backdrop for Katz, Coloyan Fleming, and Main’s study, Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development, in which they introduce the Generative AI-enabled Theme Organization and Structuring workflow, or GATOS.
GATOS is designed to explore whether open-weight generative text models, combined with machine learning techniques, can support large-scale qualitative codebook development. Importantly, the paper does not present AI as a replacement for qualitative interpretation. Instead, it asks whether parts of the codebook-development process can be made more scalable, inspectable, and reproducible. The authors also emphasize open-weight models because they may offer advantages for privacy, local control, and reproducibility compared with proprietary systems, especially when researchers are working with sensitive qualitative data.

Inside the GATOS Workflow
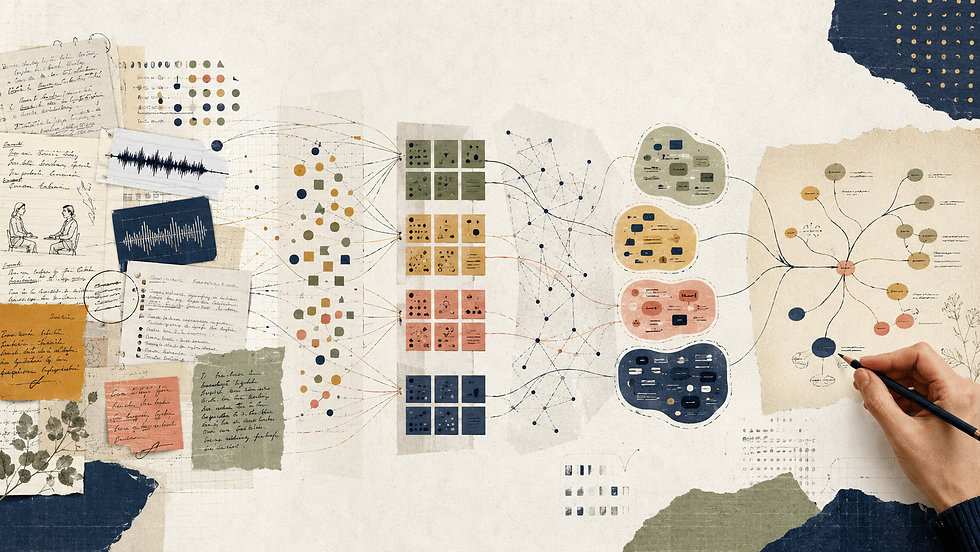
GATOS draws on aspects of thematic analysis, particularly the stages related to generating, refining, and organizing codes. Braun and Clarke’s (2006) six-phase approach to thematic analysis provides an important reference point. The workflow begins by summarizing each original text unit in relation to the researcher’s question. These summaries function somewhat like analytic memos: they identify research-relevant points from longer responses. The system then converts these summary points into text embeddings, reduces their dimensionality, and clusters semantically similar points together. For example, different comments about team leader communication might be grouped into the same cluster even if they use different wording.
The most interesting step comes after clustering. GATOS does not automatically create a new code for every cluster. Instead, it uses a retrieval-augmented generation approach. For each cluster, the system retrieves the most semantically similar existing codes from the developing codebook. The model is then prompted to decide whether those existing codes already provide sufficient thematic coverage. If they do, no new code is created. If they do not, the model generates a new code and definition.
This is the part of the workflow that most closely resembles a human coder’s practical dilemma: when is a pattern genuinely new, and when is it merely a variation of something already captured? The value of GATOS lies not only in generating codes, but in trying to avoid generating unnecessary ones.
How the Authors Evaluated GATOS
To evaluate the workflow, the authors used three synthetic datasets representing different social science contexts: teammate feedback, organizational cultures of ethical behavior, and employee perspectives on returning to the office after the pandemic. This simulation-based approach is important because the authors knew in advance which themes and sub-themes had been embedded in the data. They could therefore evaluate whether GATOS recovered the themes that were intentionally built into the synthetic responses.
This design gives the authors something qualitative researchers rarely have: a controlled benchmark. Yet that strength is also the source of its main limitation. Synthetic responses may contain known themes, but they cannot fully reproduce the ambiguity, contradiction, and contextual messiness of human-generated qualitative data. The study therefore provides early validation evidence for the workflow, rather than definitive proof that it will perform equally well in messy, real-world research settings.
The results are encouraging. Across the three datasets, GATOS recovered most of the original sub-themes. Some matches were very close. For instance, in the return-to-workplace dataset, the original sub-theme “resistance to traditional office hours” was closely matched by a GATOS-generated theme with nearly the same wording.
However, the results were not perfect. Some more complex ideas were only partially captured. For example, the original sub-theme “goals overriding ethical considerations” was closest to the generated phrase “prioritization of non-ethical factors.” This captures part of the meaning, but it loses the specific idea that organizational goals were overriding ethical concerns. Cases like this are important because they show both the promise and the limits of the method: the model can often identify the general semantic area, but it may flatten or blur the more specific conceptual relationship.

Promise, Patterns, and Remaining Questions
One notable pattern in the results is that the rate of new code creation slowed as more clusters were analyzed. This suggests that as the codebook became more developed, the model increasingly recognized when a cluster was already covered by existing codes. In a limited computational sense, this resembles the way a qualitative researcher may begin to reuse existing codes as analysis progresses. However, it should not be confused with theoretical saturation in the fuller qualitative sense, which depends on human interpretation, research purpose, and theoretical judgment.
The authors also observed an approximate 10:1 ratio between the number of simulated responses and the final number of generated themes across the three case studies. This is an intriguing pattern, but the paper treats it cautiously. It remains unclear whether this ratio is a coincidence of the study design or a pattern that would generalize to other datasets.
The workflow also raises important questions about scale. GATOS is designed for large datasets, but scale still has a computational cost. The authors note that 10,000 comments might produce roughly 50,000 summary points and thousands of clusters for the model to evaluate. In other words, AI may reduce some forms of human labor, but it introduces new demands related to computation, model selection, prompt design, and workflow validation.
Another open question concerns the level of abstraction at which codes should be generated. If codes are too specific, the codebook becomes redundant and difficult to use. If they are too broad, important distinctions may disappear. This is not only a technical problem; it is also a qualitative judgment. GATOS can assist with this process, but it cannot remove the need for researchers to decide what level of conceptual granularity is appropriate for their research question.
Conclusion
GATOS is best understood as a serious attempt to make parts of qualitative codebook development more scalable and transparent. Its contribution is not that it solves thematic analysis, but that it breaks part of the process into a structured workflow: summarization, embedding, clustering, retrieval, code generation, and theme organization.
This matters because many social science researchers face a growing mismatch between the richness of qualitative data and the practical limits of manual coding. Salomon (1991) argued for moving beyond rigid divisions between qualitative and quantitative approaches, and GATOS can be read in that spirit. It does not collapse qualitative analysis into computation, but it asks where computational tools might responsibly support qualitative work.
The key question, then, is not whether AI can replace the qualitative researcher. It is whether workflows like GATOS can take on some of the repetitive work of organizing large text datasets while leaving interpretation, reflexivity, and theoretical judgment in human hands. On that question, the paper offers a cautious but useful answer: yes, perhaps, but only if researchers remain clear about what the workflow can do, what it cannot do, and where human judgment still matters most.
References:
Braun, V., & Clarke, V. (2006). Using thematic analysis in psychology. Qualitative Research in Psychology, 3(2), 77–101. https://doi.org/10.1191/1478088706qp063oa
Katz, A., Fleming, G. C., & Main, J. B. (2026). Thematic analysis with open-source generative AI and machine learning: a new method for inductive qualitative codebook development. Humanities & Social Sciences Communications, 13(1), Article 209. https://doi.org/10.1057/s41599-026-06508-5
Saldaña, J. (2011). Fundamentals of qualitative research. Oxford University Press.
Salomon, G. (1991). Transcending the Qualitative-Quantitative Debate: The Analytic and Systemic Approaches to Educational Research. Educational Researcher, 20(6), 10–18. https://doi.org/10.3102/0013189X020006010



Comments